

第2章 GPUと計算処理の変遷
2.1 グラフィックとアクセラレータの歴史
・2020年11月時点では、スーパーコンピュータの性能をランキングするTOP500リストの中で、147システム(約30%)がGPUをベースとする計算アクセラレータを使っている。

画像出展:「NVIDIA」
『世界の最高峰のスーパーコンピュータは、これまでより高速になっているだけではありません。よりスマートになっており、多様なワークロードにも対応しています。SC20で発表された、世界最速のスーパーコンピュータ TOP500リストのうちおよそ70%、および上位10システムのうちの8システムでNVIDIAのテクノロジが採用されています。』
“Eos: The Supercomputer Powering NVIDIA AI's Breakthroughs” Youtube 2分7秒
2.3 GPUの科学技術計算への応用
●CUDAプログラミング環境
・GPUの性能を生かすには従来のOpenGLでは限界があった。これに対し、NVIDIAは科学技術計算プログラムを記述するCUDA言語とそのコンパイラやデバッガツールを提供した。
第3章 [基礎知識]GPUと計算処理
3.1 3Dグラフィックスの基本
・3次元(3D)のモデルを表示するプログラム言語はOpenGL(GLはGraphics Languageの意味)とDirectXが標準的に用いられている。前者は業界標準のKhronos Groupが管理している。後者はマイクロソフトがWindowsのゲームなどを買い開発するために作った規格である。
●[基礎知識]OpenGLのレンダリングパイプライン
・レンダリングとはデータを処理もしくは、演算により画像や映像として表示させることである。そして、モデルデータの入力から出力までの加工手順のことを、レンダリングパイプラインという。
ご参考:床井研究室 (和歌山大学の床井浩平先生だと思います)
この床井先生のホームページに知りたいことが書かれていました。それはグラフィック処理におけるソフトウェアとハードウェアの共同作業ということです。
レンダリングパイプライン
形状データから画像を生成する方法は、サンプリングによる方法(レイキャスティング法、レイトレーシング法)とラスタライズによる方法(デプスバッファ法、スキャンライン法など)の二つに大別されます。後者は座標変換により形状データのスクリーンへの投影像を求め、それを走査変換によりスクリーン上で画素に展開(ラスタライズ)して画像を生成します。これはおおよそ以下の手順に整理されており、レンダリングパイプラインと呼ばれています。

画像出展:「床井研究室」
『形状データから画像を生成する方法は、サンプリングによる方法 (レイキャスティング法、レイトレーシング法) とラスタライズによる方法 (デプスバッファ法、スキャンライン法など) の二つに大別されます。後者は座標変換により形状データのスクリーンへの投影像を求め、それを走査変換によりスクリーン上で画素に展開 (ラスタライズ) して画像を生成します。これはおおよそ図の手順に整理されており、レンダリングパイプラインと呼ばれています。』

画像出展:「床井研究室」
『最初、この手順はソフトウェアで実装されていました。しかし、CG というのは何らかの計算結果を画像化することが目的なので、画像化の作業にもCPUを使うことは無駄だと考えられました。そこで最初に、単純な整数計算とメモリアクセスの繰り返しである走査変換が、専用のハードウェアで実現されました。これにより画像生成の速度が劇的に向上したとともに、CPUは画像化の作業から開放され計算に専念できるようになりました。 』

画像出展:「床井研究室」
『モデリング変換や視野変換(この二つはまとめてモデルビュー変換とも呼ばれます)、および投影変換といった座標変換や、陰影計算 (shading) には、実数計算が含まれます。しかし、高速な実数計算ハードウェアはコストが高かったので、当初グラフィックスハードウェアには搭載されていませんでした (32bit CPU でも初期のものには内蔵されていませんでした)。この部分をハードウェアで実装したこと(ハードウェア T&L-Transform and Lighting) によって、リアルタイム3D CG が本格的に利用されるようになってきました。 』

画像出展:「床井研究室」
『レンダリングパイプラインの処理内容はここまであまり変化してこなかったので、ハードウェア化はレンダリングパイプラインの各段階の機能をハードウェアで実現する形で行われました(固定機能ハードウェア)。このため新しい機能が必要になるたびに、それを実現するハードウェアが追加されてきました。しかしCGの応用が広がり多様な表現が要求されるようになってくると、こうして機能を追加することが難しくなってきました。
そこで、機能を追加する可能性がある部分をプログラム可能にして、ソフトウェア的に機能を拡張できるようにすることが考えられました。それまで座標計算と(頂点の)陰影計算を担当していたハードウェアはバーテックスシェーダに置き換えられ、走査変換により選ばれた画像の各画素の色を頂点の陰影の補間値やサンプリングしたテクスチャの値を合成(マージ)して決定していたハードウェアはフラグメントシェーダに置き換えられました。また、フラグメントシェーダから光源情報や材質情報を参照することや、テクスチャをバーテックスシェーダから参照すること (vertex texture fetch) も可能になりました。』

画像出展:「床井研究室」
『さらに、それまでアプリケーションソフトウェア側で行われていた基本形状(点, 線分, 三角形)の生成の一部を、グラフィックスハードウェア側で行うことができるようにもなりました。これにより、アプリケーションソフトウェア(CPU)からグラフィックスハードウェアに送られる形状データの量を減らしながら、より高品質な形状の表現が行えるようになりました。これはジオメトリシェーダにより行われます。なお、ジオメトリシェーダの利用はオプションなので、使用しなくてもかまいません。 』
●フラグメントシェーダ
・OpenGLではフラグメント、DirectXではピクセルと呼ばれている。フラグメントシェーダはフラグメントの色と奥行き方向の位置を計算するシェーダ(陰影処理を行うプログラム)である。
・Zバッファは奥行き方向の座標(Z座標)を記憶する機構である。
・ブレンディングは半透明のための処理のことである。
・テクスチャマッピングはテクスチャを立体の表面に張り付ける手法である。
・ライティングは光の当たり具合、反射、光源である。
・フラグメントシェーディングは各ピクセルの明るさや色を計算すること。平面はフラットシェーディング、面の継ぎ目が目立たないようにしたのがグローシェーディングである。
・レイトレーシングは反射した光の光路を計算し、反射による映り込みを表現する。
3.2 グラフィック処理を行うハードウェアの構造
・OpenGLやDirectXで書かれたプログラムを高速で処理するのは、ハードウェアが必要である。IntelのPC用プロセッサであるCoreiシリーズプロセッサは、CPUチップの中にGPUコアを内蔵している。また、グラフィックスボードは画像処理に特化した計算を行うGPUを搭載している。

こちらは2012年のものなので、内容は古いのですが35年前(1989年)を起点に考えると約20年間の歩みが分かるので、私にとっては貴重な資料でした。(PDF11枚)
『3次元コンピュータグラフィックスをレンダリングするためには非常に多くの演算を必要とする。従来はCPU(Central Processing Unit)上でそれらの計算を行っており、計算コストが非常に高いという問題があった。そのために、産業分野などで3次元レンダリングが必要な場合には SGI(Silicon Graphics Interface)など、3次元演算専用のハードウェアを搭載した高価なワークステーションを用いていた。
一方、1999年8月にNVIDIAからGeForce256という、パーソナルコンピュータ(PC)向けグラフィックスボードが発表された。これは、PC上で1500万ポリゴン/秒及び4億8000万ピクセル/秒の描画速度を実現した。NVIDIAは、このようなグラフィック処理を行うハードウェアを GPU(Graphic Processing Unit)と呼ぶようになった。』
3.3 [速習]ゲームグラフィックとGPU
●PlayStationとセガサターンが呼び込んだ3Dゲームグラフィック・デモクラシー
・今ではNVIDIAとAMD(当時はATI Technologies)の二強時代だが、1990年代後半は数十社のメーカーがPC向けの独自のグラフィックスハードウェア製品をリリースしていた。なかでも一時代を築いたのが3dfx Interactiveで、Voodooシリーズと呼ばれるグラフィックスハードウェア製品は当時のPCゲームファンの間に絶大な人気を博していた。

画像出展:「GPUを支える技術」
ゲームには無縁の私でしたが、Voodoo PC
の名前は知っていました。
3.4 科学技術計算、ニューラルネットワークとGPU
●科学技術計算の対象は非常に範囲が広い
・科学技術計算の範囲は非常に広いが、それらに共通していることは解析しようとする現象の物理モデルを作り、そのモデルを使って現象がどのように変化していくかを計算で求めるという点である。
・スーパーコンピュータの「富岳」の課題は9つである(文部科学省の資料より)
1)生体分子システムの機能制御による革新的創薬基盤の構築
2)個別化/予防医療を支援する統合計算生命科学
3)地震/津波による複合災害の統合的予測システムの構築
4)観測ビッグデータを活用した気象と地球環境の予測の高度化
5)エネルギーの高効率な創出、変換/貯蔵、利用の新規基盤技術の開発
6)革新的クリーンエネルギーシステムの実用化
7)次世代の産業を支える新機能デバイス/高性能材料の創成
8)近未来型ものづくりを先導する革新的設計/製造プロセスの開発
9)宇宙の基本法則と進化の解明
●科学技術計算と浮動小数点演算
・お金の計算や在庫の計算などは整数が良いが、科学技術計算では非常に大きい数や非常に小さい数が出てくるため、浮動小数点演算が必要になる。
●ディープラーニングに最適化された低精度浮動小数点数
・ディープラーニングではニューラルネットワークが使われるが、入力信号に重みを掛けさらに全入力の信号の総和をとる方式のため、多少の誤差は問題にならない。そのため、半精度で問題ないと考えられている。現在では、NVIDIA、AMD、Intelが半精度浮動小数点演算をサポートしている。
3.5 並列計算処理
・2005年頃からCPUのクロック(周波数)は消費電力の問題から頭打ちとなり、各メーカーはプロセッサのコア数を増やして性能を上げる方向に舵を切った。
●GPUのデータ並列とスレッド並列
・並列処理にはそのためのプログラムが必要になる。
・1つの命令で複数のデータを処理する方式(SIMD)だが、GPUが使っているのはSIMT(Single Instruction, Multiple Thread)であり、各スレッドが1つの仕事を担当し、複数のスレッドを並列に実行するという方法である。
3.6 GPUの関連ハードウェア
●デバイスメモリに関する基礎知識
・標準的なGPUで4~8GB、ハイエンドのGPUで12~24GB。
●CPUとGPUの接続
・GPUではOSを動かさない。これは割り込みやセキュリティ機能の不足もあるが、1番の問題は並列処理では難しい命令を高速処理することができないためである。このため、科学技術計算の入力データなどはCPUに読んでもらう必要があり、CPUとGPUの共同作業になる。
・NVIDIAが開発したのはNVLinkとNVSwitchである。
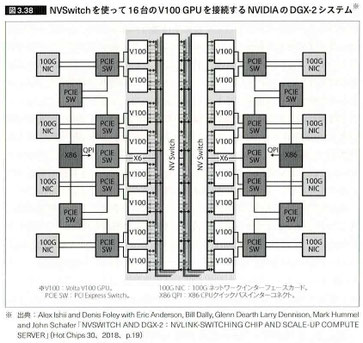
画像出展:「GPUを支える技術」
中央がNVSwitchです。
第4章 [詳説]GPUの超並列処理
・GPUはグラフィック処理を高速に実行する目的で開発されたが、その後、科学技術計算やAIのディープラーニングなどにも活用されるようになった。
4.2 GPUの構造
・GPUと300Wを消費するハイエンドGPU(NVIDIAとAMDが市場を二分する)と数Wのスマートフォン用SoCのGPUでは作りは異なる。
●NVIDIA Turing GPUの基礎知識
・NVIDIAはユニファイドシェーダ化やCUDAプログラミング言語の開発など、科学技術計算の先頭を走ってきた。さらに、ディープラーニングへのGPUの適用、自動運転車へのGPUの適用という新しい分野でも先頭を走っている。
・TuringアーキテクチャのGPUチップは「TU」が付けられ、番号は「100」が科学技術計算用の高性能チップとなっている。
●NVIDIAのTensorコア
・GoogleがTPUを自社開発し、ディープラーニング演算の性能を高めたのと時を同じくして、NVIDIAはVolta GPUの行列乗算用の演算ユニットであるTensorコアを搭載した。
4.3 AMDとArmのSIMT方式のGPU
●AMD RDNAアーキテクチャGPU
・AMDが2012年に発表したGPUはGCN(Graphics Core Next)というアーキテクチャを使ってきたが、2019年11月にRDNA(Radeon DNA)を発表し、性能/電力を50%改善したとした。
4.4 GPUの使い勝手を改善する最近の技術
●ユニファイドメモリアドレス
・ユニファイドメモリアドレスはCPUのメモリとGPUのメモリに重複しないメモリアドレスを割り当て、アドレスを見ればそれがCPUメモリかGPUかを識別できるというもの。
●NVIDIA Pascal GPUのユニファイドメモリ
・NVIDIAはPascal GPUで、ユニファイドメモリアドレスを一歩進めて、あたかもCPUとGPUが共通にアクセスできるメモリのように動作するユニファイドメモリという機能をサポートした。
4.5 エラーの検出と訂正
・宇宙線に起因する中性子の衝突で電子回路はエラーを起こす。グラフィックでは問題にならないが科学技術計算では計算途中で起こった1回のエラーが最終の計算結果を誤らせるということが起こる。問題はエラーが起こったかどうかが分からないと計算結果を信用できないということである。
●科学技術計算の計算結果とエラー
・エラーが発生していないことを100%保証することはできない。そこでエラーを見逃すことがほとんどないというシステムを作ることが重要になる。
・「エラーが起こっていない」=「エラーが起これば検出できる」という機能が必須である。
第5章 GPUプログラミングの基本
5.1 GPUの互換性の考え方
・CPUは上位互換が一般的だが、GPUはまだ発展途上の技術のためハードウェアの変更が多く、CPUのような上位互換の実現は難しい。
●ハードウェアの互換性、機械語命令レベルの互換性
・CPUの世界ではIntelのCPUとAMDのCPUは命令互換のため、Intel用とかAMD用はない。
・IBMのPOWERやArmのプロセッサ、あるいはRISC-Vの間ではハードウェアの互換性はないため、それぞれに専用のバイナリ(機械命令)プログラムを使う必要がある。
・スマートフォンなどで使われているAndroidは仮想マシンの技術を使って、異なるアーキテクチャのプロセッサを仮想的に同じハードウェアに見せることで互換性を実現している。
●GPU言語レベルの互換性
・CUDAやOpenCLという言語は多くの場合、C言語で開発されている。CUDAはNVIDIA独自の言語だが、OpenCLは業界標準のプロセッサ言語である。
5.2 CUDA[NVIDIAのGPUプログラミング環境]
・CUDAはGPUのプログラミングに必要な最低限の機能を、C言語に追加するというアプローチで開発された。
●NVIDIA GPUのコンピュート能力
・NVIDIAはそれぞれのGPUについてコンピュート能力という値を公表している。コンピュート能力はSM(Streaming Multiprocessor)の機能を公表している。
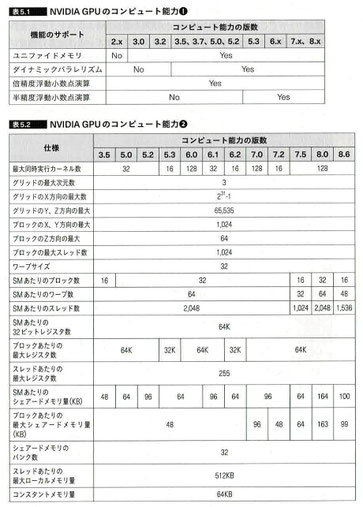
画像出展:「GPUを支える技術」
5.5 OpenMPとOpenACC
・C言語などで書かれたソースコードに、この部分はGPUを使って並列実行といった指示を書き加えるだけでGPUを使う並列プログラムを作ろうというのがOpenACC(ACCはAccelerator)やOpenMP(Multi-Processor)である。