

第6章 GPUの周辺技術
6.2 CPUとGPU間のデータ転送
・高性能のGPUでゲームをプレイする場合などは描画のために大量のデータをGPUに送り込む必要があるため、CPUとGPUの間のデータ転送速度が非常に重要である。
●NVIDIAのNVLink
・NVIDIAが開発した伝送チャネルで、伝送速度は20Gbit/sでPCI Express3.0の2.5倍の速度である。
●NVIDIA NVSwitch
・NVIDIAが2018年に開発した18ポートのクロスバースイッチで、16台のV100 GPUを相互接続できる。これにより16個のV100 GPUのデバイスメモリが連続した512GBの大きなメモリ空間になるため、どのアドレスでもアクセスしてRead/Writeできる。これによりGPU間でデータコピーする必要がなく処理の分散が容易になる。
第7章 GPU活用の最前線
7.1 ディープラーニングとGPU
・ディープラーニングの計算処理の大部分はGPUが得意な行列の積の計算である。
・NVIDIAは自動運転用のGPUを内蔵したSoCを製品化している。
・自動運転、車の自動化にはAI用のGPUが搭載される可能性がある。
・画像認識はロボットや自動運転車の眼として重要な技術で、従来は画像認識の専門家がシステムを作っていたが、2012年にディープラーニングを使ったシステムが従来のシステムを大幅に上回る成績を達成したことから、画像認識の研究はディープラーニング中心になった。
・認識精度の向上につれて、ニューラルネットワークの規模も拡大されてきている。2020年のOpenAIの自然言語処理システムGPT-3では175B(175兆個)パラメータという巨大モデルが出現している。(GTP-4のリリースは2023年7月、GTP-4 Turboは2023年11月)
●ディープラーニングで使われるニューラルネットワーク
ネットには多くのサイトや動画がありましたが、特にいいなと思ったサイトをご紹介させて頂きます。


『本記事では、膨大なデータを分析・解析を行うためにAIの導入を検討している人向けに、ニューラルネットワークの仕組みや関連用語などを中心に解説します。また、活用事例も紹介するので、今後のAI導入の参考にしてください。』

”ニューラルネットワークとは?仕組みや歴史からAIとの関連性も解説”
『この記事では、ニューラルネットワークの基礎知識から代表的な種類、変遷の歴史まで解説します。AI技術やディープラーニングとの関係についてもわかりやすく説明しますので、AIサービスの研究や開発を検討する際にぜひ参考にしてください。』

”AIビジネスを考える上で押さえておきたい、ニューラルネットワークの実用例30選”
『人工知能分野のニューラルネットワークは、人間の神経回路の仕組みをまねる、機械学習の一手法です。 さまざまな分野でのビジネス利用が活発になり、大きな成果をあげる実例も出ています。』

”大規模言語モデル(LLM)とは? 仕組みや種類・用途など”
『近年ではさまざまな生成AIが登場していますが、そのなかでも注目を集めているものが「大規模言語モデル(LLM)」を活用したものです。以前からコンピューターと対話する形のAIは存在していましたが、大規模言語モデルの登場により、その精度は格段に向上しました。従来の言語モデルと比べて大規模言語モデルはどのような特徴を持つのでしょうか。』
●ディープラーニングで必要な計算とGPU
・推論やディープラーニングの学習も大量の行列と行列の積の計算が必要なので、GPUであればCPUよりはるかに高い処理性能が期待できる。
・ディープラーニングの推論は、16ビットの半精度浮動小数点、あるいは値を適切に量子化すれば、8ビットの固定小数点で計算してもほとんど推論結果には影響がない。
●ディープラーニングでのGPUの活用例
・画像認識は多くの分野で利用が始まっている
-ドローンの眼として画像認識の必要性が高まっており、低電力のGPUのシステムが開発されている。
-セキュリティ用の監視カメラに対し、状況の危険度の判定や通報、不審者の顔認識をすることで大幅に機能を高めることができる。
-医療画像の読影はディープラーニングにより、細かい病変の発見に貢献できる。ただし、医療機器としての活用には大量の事例による有効性の検証が必須である。
・NVIDIAは自動運転に向けたSoCに注力
-自動運転には画像認識が重要であるが、大量の計算が必要である。
-NVIDIAは自動運転を次世代のビジネスの柱として、2019年にDrive AGXOrinを発表した。
-NVIDIAは2000TOPS(Tera Operations Per Second)のコンピュータではレベル5のロボタクシーの実用化を目指している。
-NVIDIAは、AIスパコンを自社に設置し、いろいろな天候や周囲の明るさのシナリオを生成したり、実際には存在していない色々な障害物(子供の飛び出しや、前の車の落とし物など)をシナリオに加えたりして、自動運転システムを学習させてAIの品質改善を続けている。

画像出展:「GPUを支える技術」
7.2 3DグラフィックスとGPU
●VR、ARの産業利用
・VRはVirtual Reality、ARはAugmented Realityである。
●NVIDIAのGRID
・NVIDIAは中央のサーバと仮想化された端末で、各端末のGPUを搭載することなく快適なグラフィックススピードを提供できるNVIDIA GRIDというシステムを提供している。

”仮想デスクトップのグラフィックス処理を高速化「NVIDIA GRID」”
こちらの記事はアセンテック(株)さまからです。
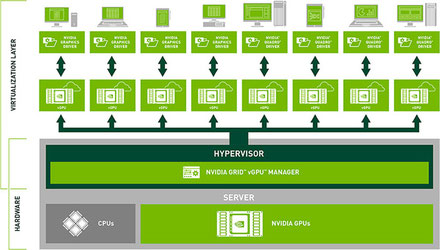
図はNVIDIA GRIDのシステム構成図です。
また、同ページにに”動画:NVIDIA GRID CPU と vGPU の対照比較 ”がありました。(1分19秒)
タイトルは「NVIDIA GRID vGPU vs. CPU Only - Siemens NX Horizon View with VMware Horizon & vSphere」です。
●物理的に複数ユーザーにGPUを分割するMIG
・MIG(Multi Instance GPU)はAmpere A100に付加された機能で、7個のGPUを個別のユーザーに割り当てるもので、他のユーザーの影響をほとんど受けない独立性の高い分割使用環境を実現する。
7.4 スーパーコンピュータとGPU
●世界の上位15位までのスーパーコンピュータの状況
・スーパーコンピュータの世界には、TOP500という性能ランキングがある。
・GPUの課題はプログラミングが難しいことがある。

『TOP500 プロジェクトは、7 年間使用されていたマンハイム スーパーコンピュータの統計を改善および更新するために 1993 年に開始されました。
当社のシンプルな TOP500 アプローチでは、「スーパーコンピューター」そのものを定義しませんが、ベンチマークを使用してシステムをランク付けし、TOP500 リストに入る資格があるかどうかを決定します。 』

こちらの記事は「ITmedia」さまより拝借しました。

『同社が独自に開発したデータセンター規模のスーパーコンピュータ「Eos」をブログと動画で披露しました。 』
写真をクリック頂くと、動画“Eos: The Supercomputer Powering NVIDIA AI's Breakthroughs”がご覧頂けます。(2分8秒)
第8章 ディープラーニングの台頭とGPUの進化
8.2 各社のAIアクセラレータ
●GoogleのTPU
・Googleはデータセンターの負荷が2倍になった場合、それをCPUの増設で対応するのは高コストのため、ディープラーニングの計算を効率的に行うことができるハードウェアの開発に着手した。
・Googleは学習時間を短縮するため、多数のTPU(Tensor[線形的な量または線形的な幾何概念を一般化したもの] Processing Unit)をネットワークで接続したマルチTPUのディープラーニング用のスーパーコンピュータを作ることになった。

画像出展:「GPUを支える技術」
右端が演算回路部分で、重みを供給する重みFIFO(First In First Out) 、行列積を計算するマトリクス乗算ユニットMXU(Matrix Multiply Unit)がある。
●NVIDIAのTensorコア
・計算回数に比べメモリアクセス回数が少なく、メモリアクセスがボトルネックにならず演算性能を出しやすい。

『NVIDIA A100 Tensor コア GPU は、あらゆる規模で前例のない高速化を実現し、AI、データ分析、および HPC 向けの世界で最も性能能力の高いエラスティック データ センターを強化します。』
●Habana LabsのGoyaとGaudi
・Habana LabsはイスラエルのAIチップメーカーだが、2019年12月にIntelに買収された。
・Goyaはデータセンター向けの推論アクセラレータ、Gaudiはデータセンター向けの学習アクセラレータである。
8.3 ディープラーニング/マシンラーニングのベンチマーク
●MLPerfベンチマーク
・MLPerfはディープラーニングの実行性能を測るベンチマークである。

『学界、研究機関、業界の AI リーダーたちによるコンソーシアムである MLCommons によって開発された MLPerf™ ベンチマークは、ハードウェア、ソフトウェア、サービスの学習と推論の性能を公平な評価を提供するように設計されています。』

“NVIDIA、MLPerf ベンチマークで生成 AI トレーニングを飛躍的に加速”
『10,752 基の NVIDIA H100 Tensor コア GPU と NVIDIA Quantum-2 InfiniBand ネットワーキングを搭載した AI スーパーコンピューターである NVIDIA Eos は、1,750 億のパラメーターを持つ GPT-3 モデルを10 億のトークンでトレーニングするベンチマークを、わずか 3.9 分で完了しました。』
8.4 エクサスパコンとNVIDIA、Intel、AMDの新世代GPU
●NVIDIAのAmpere A100 GPU
・GoogleのTPUはディープラーニングの学習と推論計算を効率よく実行する専用チップだが、NVIDIAのA100 GPUはグラフィックスや科学技術計算、データ解析、クラウドゲーミング、遺伝子解析などさまざまな用途のアクセラレータとして使えるように設計されている。

画像出展:「GPUを支える技術」
●Intelは新アーキテクチャのXe GPUを投入
・グラフィックスの世界はNVIDIAとAMDの独占状態だったが、グラフィックスだけでなく科学技術計算やディープラーニングの分野でも広く使われるようになってきて、Intelの牙城であるデータセンターをNVIDIAやAMDのGPUが侵食してきている。
●AMDは新アーキテクチャCDNA GPU開発へ
・AMDは2020年11月に大規模科学技術計算やディープラーニング計算をターゲットとするCDNAアーキテクチャを発表し、Instinct MI100 GPUを発表した。
8.5 今後のLSI、CPUはどうなっていくのか?
●微細化と高性能化
・現状で微細なパターン描画の最大の障害は光の波長である。
・EUV波長で乱れのない凹面反射鏡のレンズは特殊技術が必要で、ドイツのZEISS(ツァイス)は作ることができる。そして、このレンズを使うEUVの露光機を作れる会社はオランダのASMLである。
・微細化はスローダウンしながらも進歩している。しかし、厚みは薄くても高い電圧に耐える絶縁膜材料を探すというアプローチは原理的には可能だが、加工法などを含めて代替になる新材料の開発には長い時間が掛かるため、険しい道と考えられている。

『EUV露光は、7nm以降の微細回路パターンをシリコンウェーハ上に転写(露光)するための技術として、2019年に台湾のTSMCによって初めて量産投入された技術である。』
●チップレットと3次元実装
・業界で期待されているのは3次元実装である。なかでも一番実用化が進んでいるのがHBM(High Bandwidth Memory)である。
“「HBM(High Bandwidth Memory)」とは”
“NVIDIA、HBM3eメモリ採用の次世代GH200を発表”
●CPUはどうなっていくのか
・CPUは量的にはスマートフォンなどのSoCに使われるのが大部分である。また、IoTも主要なCPUユーザーになっていくと考えられる。一方、売り上げや利益の面では、クラウドサービスを提供する大規模データセンターがCPUの主要なユーザーである。従って、この2つの分野に向けてCPU開発が行われていくと考えられる。一方、ArmアーキテクチャのCPUをデータセンターに使おうという動きもある。その代表がAmazonのAWS Graviton CPUである。AmazonはArmのNeoverseアーキテクチャのデータセンター用のCPUを自社で開発し、使用している。
・Armアーキテクチャはサーバ市場における普及の入り口に立っているかもしれない。
8.7 まとめ
・重要なことはCPUとGPUは適材適所で仕事を分担することである。微細化はかなり進んできており、微細化だけで約10倍のトランジスタが使えるようになると予想されている。さらに3次元実装を組み合わせれば、さらに10倍以上はいけるので、CPU、GPUには大きな進化の余地は残っている。一方、大きな問題は発熱で、これには消費電力を減らすことが最も重要になる。そのために、半導体技術、回路設計技術、論理設計技術、アーキテクチャの各分野で努力が続けられている。
・GPUメーカーは並列プログラミングとCPU-GPU分離メモリから生じるプログラミングの難しさの軽減にも取り組んでいる。そして、GPUの使用分野の拡大にも力を入れており、ますます私たちの生活の中に入り込んできている。
・『本書では、GPUとはどのようなものなのか、なぜ計算性能がCPUより格段に高いのか、GPUのプログラミングはどのようにするのか、さらにニューラルネットワークの計算はどのように行われるのかなどの基本事項とともに、最新の話題や将来の見通しを含めてGPUについて解説しました。』
感想
第1章に「文字だけでなく図が加わると、情報の伝達が飛躍的に容易になる」ということが書かれており、「これだ!」と思いました。
例えば、営業でプレゼンテーションを行う場合、文字だけでなく図や表、あるいはイラストや動画などを使って効果的に説明します。また、理解する側の立場にたっても、特に目新しいことについては、文字情報だけでは理解が難しいということが多々あります。ブログの冒頭にご紹介した設計システムのCADも、2次元の製図より3次元の立体モデルの方が、デザイン、設計、製造など開発・生産の各工程に関わる人の理解を助けます。
人の気持ちを理解する場合、特に隠れた「気持ち」は微妙に表情に出ることが多く、言葉に加え目からもたらされる視覚情報は、その人の気持ちや考えを深く理解する上で、非常に役に立ちます。これらは“非言語コミュニケーション” と言われています。
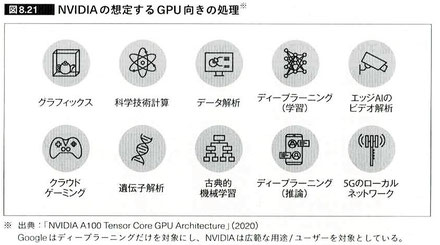
画像出展:「GPUを支える技術」
上記はNVIDIAの資料で、GPUの主な用途が紹介されています。これらのコンピューティングには文字だけでなく、画像や映像の情報処理が強く求められます。
個人的には、AIはニューラルネットワ-クという新しいコンピュータ言語によるITの革新のように思っていましたが、それに加えて、非言語コミュニケ-ションのコンピュータ化という側面もあるように感じました。
ご参考:【GTC】2024年3月18日-21日
NVIDIAが3月18日から21日までの4日間、カリフォルニア州サンノゼの サンノゼ マッケンナリー コンベンション センターでカンファレンスを行いました。興味があったので登録してみたところ、毎日メールが届き、以下のようなサイトに案内されました。

“GTC March 2024 Keynote with NVIDIA CEO Jensen Huang”
まさに『産業の米、AIの米』だと思いました。クラウドAIからエッジAI、そして、開発支援、トレーニング(学習)など、AIの全てを網羅しているという感じです。
※医療(Healthcare):“Healthcare Reimagined with Artifi” 1分35秒
※ロボット:“NVIDIA Robotics: A Journey From AVs to Humanoids” 3分42秒
※自動運転:”NVIDIA AI Tools for Autonomous Vehicle Developers” 2分23秒
※3D共同開発プラットフォーム:“NVIDIA Omniverse Cloud APIs on Microsoft Azure” 1分36秒
※CEO ジェンスン・フアン:“Jensen Huang, Founder and CEO of NVIDIA” 56分26秒
News(2024年7月26日):“中国「無人タクシー」急増 実際に乗ってみた” (YouTube 5分47秒)

画像出展:「中国で「無人タクシー」が急増 実際に乗ってみた(FNNプライムオンライン)」
なんと、中国では既に無人タクシーの営業が始まっていました。北京、重慶、広州市など全国4カ所で営業スタート。2025年までに中国の全国で無人タクシーを導入したいとのことです。
日本では過疎化する高齢者地域の交通手段として、とても魅力的ではないかと思いました。
ご参考(2024年9月12日):GPUを取り巻く新しい動き(AIを加速させる新しい技術や取り組み等が動いています)

こちらは、週刊エコノミスト2020年2月4日号です。AIチップの動きは、ここ1、2年の動向かと思っていましたが、もっと前からの動きでした。
『最初の口火を切ったのはグーグルだ。2016年5月、エヌビディアのGPUよりも消費電力が1ケタ小さいAIチップ「TPU(テンソル・プロセッシング・ユニット)を開発し、2015年から自社のクラウドで検索エンジンに使っていたことを明らかにした。省エネの鍵となったのは、演算精度を16ビットから8ビットへ半分に落としてもAIの性能はほとんど変わらず、消費電力は1ケタ小さくなるのを見いだしたことだった。TPUはその後も改良を重ね、2018年にはクラウドでなく、端末に組み込む「エッジTPU」も発表している。TPU以降、性能に支障ない範囲でいかに演算精度を下げて消費電力を抑えるかが、開発競争の中心になっていった。』
1.AI ASICチップ: ハイテク大手のAI軍拡競争における次のフロンティア
3.ASIC市場の革新と未来: 最新トレンドと成功事例に学ぶ2024年の展望
4.密かに進化するAIチップ IT/半導体業界は半世紀に1度の大変革か?
5.AMD・Intel・Google・Microsoft・MetaなどがNVIDIA対抗のAIアクセラレータ相互接続規格の開発に向けて業界団体を設立
6.胎動する「ポストGPU」、NVIDIAのボトルネック狙う米スタートアップの最終兵器
→d-Matrix:AIを持続不可能なものから実現可能なものに変える。